The real capabilities of an agentic AI system stem from its ability to tackle scientific research. Scientific research includes insufficient evidence on trusting results, constant failures, and uncertainty. Scientists must perform difficult experiments, troubleshoot answers, assess translational risks, and ponder the next steps. Prior AI benchmarks failed to capture the actuality and focused on structured questions. To tackle this, researchers developed LifeSciBench, a benchmark created to assess whether artificial intelligence systems can support science research workflows.
What Does LifeSciBench Measure?
LifeSciBench marks whether artificial intelligence systems can complement science research tasks and not just answer structured questions. It strives for accuracy to create a question for life scientist about their workflows and methodologies in applied research settings. Based on those answers, the tasks were categorized into seven different workflow categories: evidence handling, analysis, design and optimization, scientific reasoning, validation and operations, translation, and scientific communication.
Each task resembles a scientific request that would educate the collaborator. It includes prompts, any information or content, or materials, and required free-response answers. With reference to the text, it can generate accuracy, justification, caveats, and limitations that the scientist would formulate.
Life segments stand 750 authorized tasks across seven workflows and biological issues. The tasks were generated by 173 scientists, all with PhD-level training and knowledge in biotechnology or the pharmaceutical sector. Tasks were re-developed multiple times with no tangible limits on revision rounds. On average,selected tasks went through six sovereign cycles and two rounds of expert review. The outcome is based on average or accurate answers and expert consensus, with 90% agreement among the reviewers in the specific domain.
This helped ensure that these tasks were scientifically relevant, readable, and representative of the applied research rather than academic knowledge. The benchmark is created to resonate with the difficulty of real-life science work.
79% of tasks need multiple reasoning and decision-making, with an average of four steps per task. LifeSciBench contains 1,062 attached artifacts such as numericals, figures, tables, 3DMs, structures of chemical sites. Several tasks require two models to understand, process, or synthesize information from one artifact rather than solely relying on the prompts.
Read More: OpenAI Launches Partner Network: What It Is & How to Join It?OpenAI
How Are Models Evaluated in LifeSciBench?
Lifestyle bench inculcates comprehensive, task-centric grading rubrics. These rubrics assemble responses into scientific claims, outcomes, calculations, justifications, decisions, and other elements. Across this benchmark, rubrics contain 19,000 individual criteria, ranging above 25 criteria per task. This process shows how scientists work, stems from continuous practice. An outcome may reach an accurate endpoint, but still appear incomplete if it overlooks a crucial disadvantage or fails to address a quintessential caveat.
In contrast, a response may contain high-end reasoning and fail to complete the task. SciBench evaluates a model on two basis, where the model reaches the right answer and comes to be scientifically valid and operational. Benchmark validation was facilitated through sovereign expert review by 453 reviewers who did not write the task. Most reviewers hold PhD degrees with detailed experience and strong publication records. The reviewer’s agreement exceeded 96% across several categories including rigor, realism, and usefulness of the model.
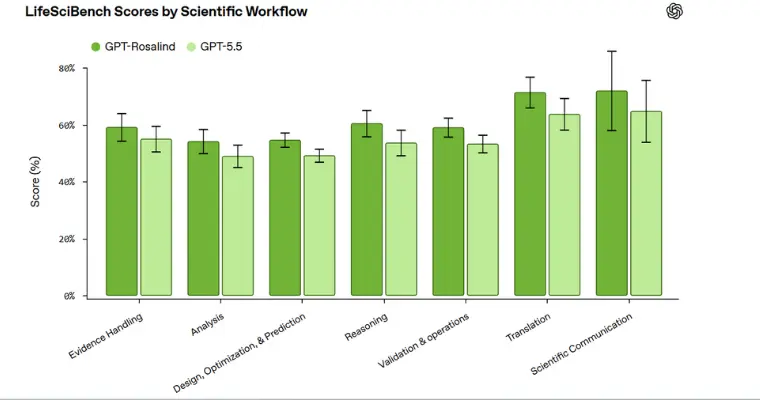
LifeSciBench shows two outcomes: the score and the pass rate. The pass rate measures how regularly a model finishes the task and gives a certain amount of credit for individual rubric criteria, even when a task isn’t completed. Both metrics matter, as scientific responses can be partially accurate or useful, even without being completely solved. The outcomes show that the artificial intelligence model’s performance differs by task type and workflow.
The models perform better when the tasks are based on scientific synthesis, structured interpretation, and communication. Progress is viable in scientific communication and translation tasks, requiring improvement in organizing evidence and joining preclinical findings to implications.
On the contrary, performance remains weaker on design-heavy or artifact-heavy tasks, tasks that require massive information from complex figures, large files, or creating numerically structured outputs remains difficult. In many cases, models secure substantial partial credit, but fail to assess the restrictions, identify incorrect evidence, or adjoin the dots from reasoning to decision.
LifeSciBench is a step forward to measure how artificial intelligence systems can work for scientific research. The benchmark focuses on generated tasks that represent industry workflows while leaving scientific specialties and extensive research outside its scope. Suitable performance in LifeSciBench is evidence of task capability, not a direct measure of downstream research impact. The next step is to align benchmark outcomes with real-world deployment that examines whether artificial intelligence systems truly support the research and discovery.