Chinese AI lab Z AI launches GLM 5.2, which is an open-weight model built for lengthy engineering tasks. The early benchmark rankings show its early competitiveness. In the non-agentic web development sector, GLM 5.2 surpasses Claude Stable on the Design Arena leaderboard, taking the top positions based on Elo ratings. This outcome emphasizes the model’s ability, including raw context length, to apply in long contexts easily in practical coding environments. Rather than focusing on agentic autonomy, the ranking emphasizes how GLM 5.2 performs in user-centric development tasks.
What is the Outcome for Design Arena?
On the design arena non-agent leaderboard, GLM 5.2 ranks the highest by Elo rating, overtaking Claude Fable. The non-agentic category inspects models and tasks where users directly ask the system without sovereign planning loops or tool-driven agents. The leaderboard calculates performance across pitch site development, game development, data visualization, 3D tasks, and UI components, each calculated as a single file execution output.
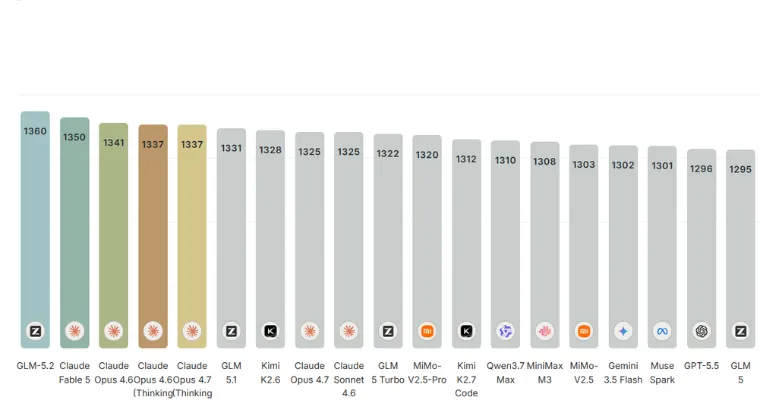
These leaderboard rankings reflect real-world user preference signals rather than test cases. In this environment, GLM 5.2 scores the highest overall, placing it above Claude Fable and other similar competing models. This outcome also shows that GLM 5.2’s long short-text design produces better outcomes even when the workflow does not depend on agentic reasoning or several-step autonomy.
GLM 5.2 is created to make lengthy engineering feasible rather than just being present. The model delivers a better lossless 1 million token context and has been developed under months of specialized training for long-context coding environments. This allows the entire codebase or long-horizon contexts to be managed within a single reasoning workflow. In the non-agentic environment, this shifts into strong project-level coherence, better execution across lengthier inputs, and lower dependency adherence to productive engineering standards.
Instead of bifurcating a task or losing the restrictions mid-generation, GLM 5 maintains continuity across lengthy instructions, which is essential in web development and UI-embedded outputs evaluated by the design arena. The result indicates that long-context dependency benefits even single-prompt workflows, not only sovereign agent systems.
Also Read: How Sarvam AI’s $234M Unicorn Round Reflects on India’s Two-Pronged AI Framework
How Does the Result Fit With Broader Benchmark Outcomes?
The design arena ranking resonates with GLM 5.2 comprehensive benchmark outcomes. In long-context coding, across Frontier SWB post-trained bench and SWB marathon, GLM 5.2 consistently ranks with the best performing open-source models and is in close proximity with closed-source leaders. On standard coding benchmarks, GLM 5.2 depicts large gains over its previous model, GLM 5.1, including massive developments on terminal bench 2.1 and SWB bench pro.
These betterments indicate that the model’s infrastructure and training benefit long-horizon projects and shorter non-agentic tasks altogether. The design arena outcomes add an additional layer, which is GLM 5.2’s advantages, viability in formal benchmarks, and in preference-driven real-world calculator settings.
By ranking high on the non-agentic web development leaderboard, GLM 5.2 depicts that open-source models can outrank big LLM models in practical workloads. The outcomes emphasize that gains in long-context architectural efficiency and training can affect user-centered quality. Rather than depending on sovereign agents or advanced tooling, GLMs’ performance reflects gains in core reasoning, context retention, and execution reliability. This places it as a strong base model for those developers who want high-end outputs without complexities in agent orchestration.
GLM 5.2’s higher ranks on the Design Arena non-agentic leaderboard highlight a cornerstone for open-source ecosystems. By surpassing Claude-Fable in direct web development workloads, the model shows that long-context capabilities deliver better tangible benefits, even in user-centric tasks. Combined with its benchmark results, the ranking redeveloped GLM revamps GLM 5.2’s position as a better, suitable, and high-performance open-weight model, not just for experimentation, but for daily use.