- NVIDIA launches Nemotron 3 Ultra, a 550B-parameter model built for lengthy multi-agent structures.
- The model’s base is Multi-Teacher On-Policy Distillation, which allows stronger outputs across various niches with fewer inefficiencies.
- Nemotron 3 Ultra uses 55B parameters per inference, allowing frontier-level outputs with lower token usage and 30% price reduction.
- NVIDIA places itself as an orchestrator, managing complex reasoning.
Nemotron 3 Ultra represents Nvidia’s comprehensive strategy of embedding open models for enterprise infrastructure rather than chatbot systems. By focusing on streamlining the work rather than execution, the model resonates with real-world AI agents. In a world where AI agent interactions heavily influence token costs, this strategy aims to save tokens for greater utility.
Most LLMs are used for short conversations rather than lengthy decisions. In the real world, fewer models are used for in-depth reasoning. This imbalance causes problems for developers building high-end systems. NVIDIA’s Nemotron 3 Ultra, an open-source model designed for optimizing agents, tackles this exact problem. By blending effectiveness with multi-teacher on-policy distillation, it aims to reduce token usage while preserving quality.
What is NVIDIA Nemotron 3 and Its Usage?
NeMo 3 refers to a 550B-parameter model with 55 billion parameters allotted for inference. This feature makes it more efficient than other models. It is embedded to act as an intelligence layer, which takes care of organizing and planning for heavier tasks. The model aims to use cases where AI agents must possess coherence, such as managing evidence and dealing with system constraints.
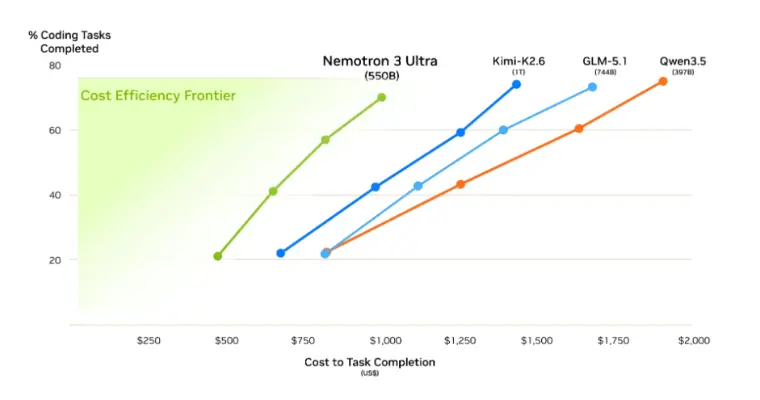
According to NVIDIA, Nemotron 3 Ultra has 5x higher throughput than other models in its range, allowing long workflows to run smoothly. The model uses fewer tokens and helps cut costs, with 30% reduction for AI workflows. The focus on token effectiveness adds relevancy as proprietary organizations shift from pilots to production-grade agent workflows. Lower token consumption also reduces content swerving, a major inefficiency in long-running multi-agent systems.
How Does Multi-Teacher On-Policy Distillation Work?
The distinct technical aspect behind Memotron 3 Ultra is Multi-Teacher On-Policy Distillation. Instead of learning from a single model, Ultra is taught using more than 10 teacher models, each focusing on a different niche, such as theory, reasoning, research, or legal analysis. During its course, Nemotron 3 Ultra creates its own outputs with the given task and receives reward signals from each model. These outputs are then evaluated, allowing teacher scoring and proper optimization to run in parallel.
This process improves training and information abilities. After each training course, the improved evaluations are used to generate different teacher models, creating a loop where the student and the teacher model co-evolve. This allows Memotron 3 Ultra to possess intellect across diverse niches without excessive token use.
Also Read: NVIDIA JetPack 7.2 Reduces Dependency and Power Custom Linux Systems
Hybrid Mamba-Transformers And Multi-GPU Deployment to Optimize Agentic Workflows
Ahead of training procedures, Neutron 3 Ultra has several infrastructures to bolster multi-agent architectures. A hybrid Mamba transformer architecture helps to boost efficiency for long workflows. The model also contains latent MOE routing to boost code generation and tool use. Multiple-token prediction reduces latency by processing multiple tokens.
Additionally, Neutron 3 Ultra also has an NBFV4 checkpoint across NVIDIA Hopper, Blackwell, and Ampere GPUs. This helps developers deploy models across different generations, achieving 5x higher throughput compared to BF16 precision on Blackwell GPUs.
The launch of Neumotron 3 Ultra shows a comprehensive shift in separating Frontier models from lengthy executive models. Instead of relying on a costly model, developers streamline workflows with Neumotron 3 Ultra and handle routine tasks with smaller models. By focusing on effectiveness, accountability, and agent-focused patterns, Nvidia places Neumotron as a scalable infrastructure for AI agents.