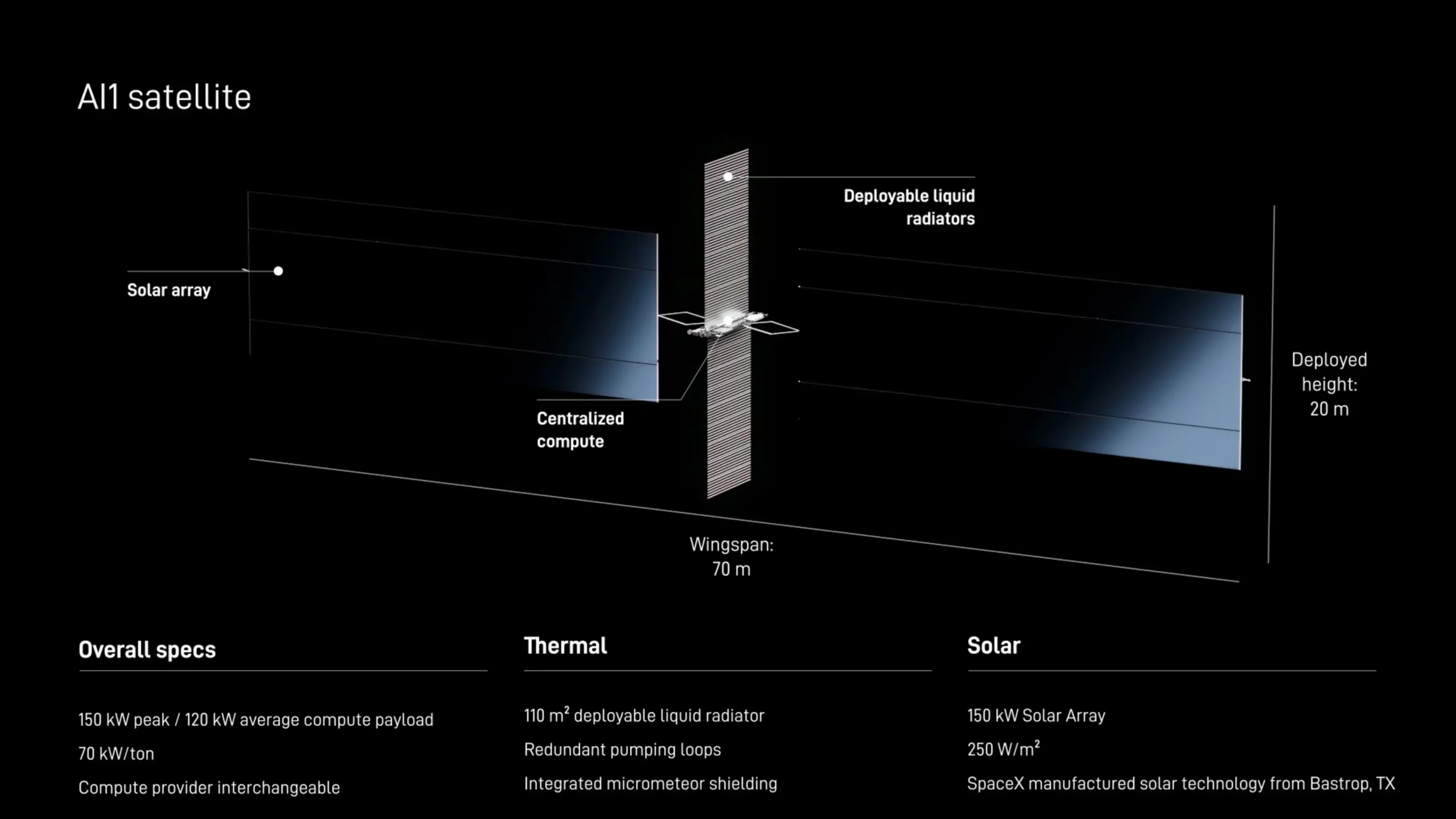
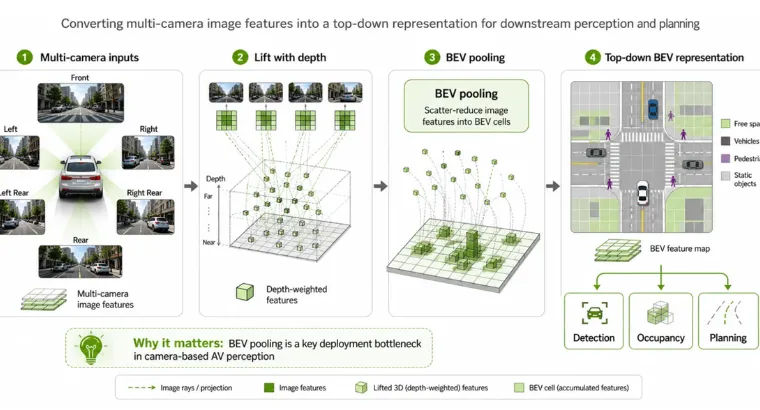
Bird’s eye view visibility is a common pattern in self-driving vehicles, spatial AI systems, and robotics. By projecting different views through BEVPoolV3 into one grid, BEV-based pipelines provide visibility with a consistent representation of the surroundings. This feature eases reasoning about obstacles, other vehicles, lanes, and trajectories. A key feature within this is BEV pooling, which blends image features and scatter reduces them into BEV grid cells. While the concept is simple, BEV pooling causes latency in real-world adoption due to insufficient memory access, repeated reads, scatter-reduce behavior, and sensitivity to GPU cache. BEVPoolV3 addresses these issues through kernel-level optimization on NVIDIA GPUs.
How Does BEVPoolV3 Reduce Time Gap?
BEV pooling converts camera-focused feature maps into a single top-down representation that resonates in real-time. It collects image features, weights them using depth context, and scatter-reduces the outcome into BEV grid cells that can be used for detection, mapping, and organizing modules. This operation is difficult to manage. It uses irregular memory access designs, repeated loading of scatter indices, and merging multiple points mapped to the same BEV cell. These features lead to insufficient cache usage and high memory demand, particularly when the output exceeds the capacity of the chip.
Prior approaches, such as BEV-PoolV2 launched adoption-centric improvements for BEV-Det-style models, while DET outer traversal approaches, inclusive of those used in CUDA-BEVFusion, facilitating decreased repetition over BEV intervals. BEVPoolV3 proceeds in a similar direction and follows the same pattern. It has also introduced four additional changes, such as decreasing duplicate loads, changing packed scatter records with a five-array int32 scatter map, precomputing indices to reduce runtime, and allocating exclusive ownership of output intervals. These new changes reduce memory traffic and overhead without affecting the computation.
The evaluation emphasizes two NVIDIA RTX GPUs with different cache sizes: the NVIDIA RTX A6000, which has a 6 MB L2 cache, and the RTX PRO 6000 Blackwell Max-Q workstation edition, which has a 128 MB L2 cache. Using outcomes derived from a new scene sample, approximately 209,000 scatter points, 80 feature channels, and a 49 MB BEV pooling workset, the workflow exceeds L2 capacity on RTX A6000 class hardware but is appropriate within L2 on Blackwell-class GPUs. As an outcome, the same BEV pooling method becomes DRAM-bound on one GPU and largely L2-resident on the other, leading to different approaches, outcomes, and optimization needs.
How is Kernel Different for GPU Infrastructures?
In the BEVPool V2 style, the channel causes a constant scatter index as a repetitive mechanism. For example, with 80 channels and an 8-channel tile size, it is reloaded 10 times, increasing the memory traffic. BEVPoolV3 solves this issue by using depth-first outer traversal and interval definitions. Starter indices are in separate INB32 arrays, rather than a unjogged infrastructure, leading to better alignment and addressing threads for efficient outcomes. Interval-only traversal makes sure that each BEV cell passes through one time, decreasing write contention.
While the foundation remains the same, BEVPoolV3 uses distinct kernel specializations depending on the GPU’s memory. On small L2 GPUs, such as RTX A6000, the process focuses on reducing memory traffic through accumulation, fewer channel passes, and cache streaming to avoid eviction of index data. On large L2 GPUs, such as RTX PRO 6000 Blackwell Max-Q, where the work is embedded in cache, the focus is on effectiveness and occupancy. Precomputed index, loads, and FP8 specialized inner loops are embedded to decrease overhead and improve the overall output. Profiling with NVIDIA Nsight Compute shows that these kernels depict different issues depending on cache storage, ranging from DRAM bandwidth issues to instruction constraints.
BEV pooling trail depicts how utilizing BEV pooling demands an in-depth knowledge of characteristics and GPU hierarchy. The outcome shows that the efficiency gains are not solely because of a change in algorithm, but resonating kernel design with the issue. Whether the issue lies within bandwidth, cache, or instruction throughput. Ahead of BEV visibility, the same clauses apply to other gather and scatter heavy workflows such as voxelization, sparse embeddings, and augmented reductions. Bifurcating the memory regime, reducing redundant memory traffic, and optimizing assumptions through profiling remain key to achieving persistent output across GPU infrastructures.