

Key Highlights:
- Google Gemma introduces a new multimodal AI, bridging the gap between edge models and larger systems.
- An encoder-free infrastructure reduces the possibilities of latency and memory usage.
- Despite its effectiveness, Gemma 4 12B lags behind other models in efficiency and ability.
Google introduced Gemma 4 12B, planning to bring multimodal brilliance to laptops. It is a mid-sized model, in between Gemma E4B and the large 26B models. It is the first of its kind to support local audio input in agentic workflows. Surpassing 150 million downloads reflects the surging demand for open-source and native AI systems.
While the model is innovative, its competitiveness will be susceptible when compared to other models. Beyond the statistics, Gemma 4 12B remains distinct for its encoder-free architecture, allowing inputs to directly embed into the model. Its ability to run natively with 16GB memory places it as a suitable option for privacy-sensitive work structures.
How Does Gemma 4 12B Perform Against Similar and Different Models?
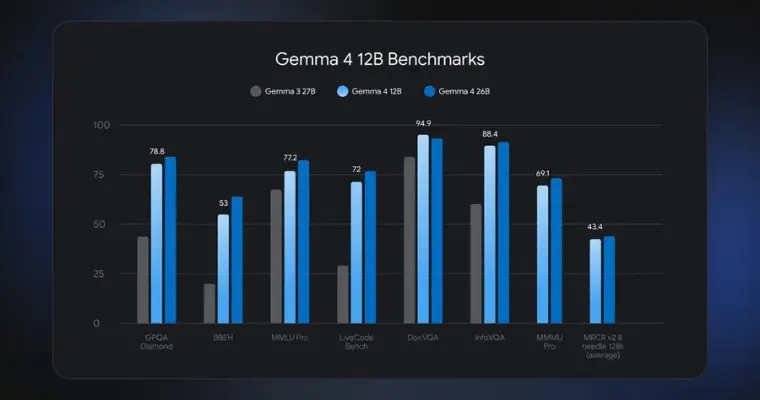
The benchmark indications show Gemma 4 12B ahead of prior models across different niches. The new model consistently outperforms Gemma 3 27B despite a smaller memory. On GPQA Diamond and MMLU Pro, Gemma 4 12B outperforms Gemma 3 27B in reasoning and is in closer proximity to 26B models.
The strongest juncture is in DocVQA, where Gemma 4 12B is closer to the 90s, matching the larger 26B model. This proves that removing the encoder architecture does not weaken the model and improves efficiency. On benchmarks such as LifeCodeBench and MMLU Pro, Gemma is far behind the 26B model, limiting architectural efficiency.
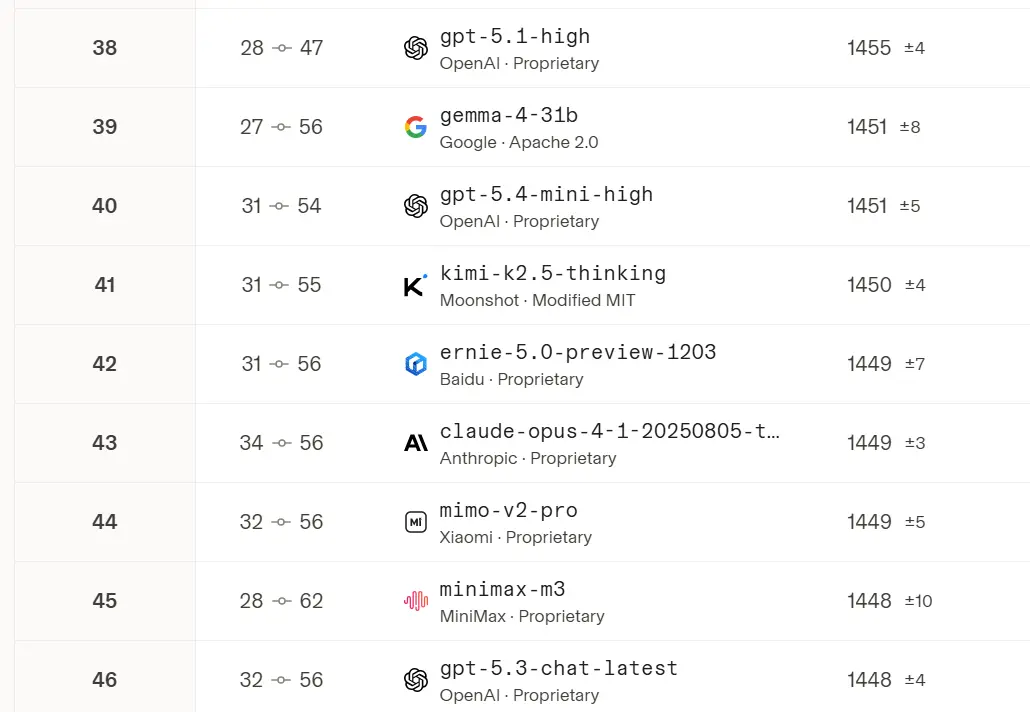
It also reveals that Gemma 4.31B ranges higher than models like GPT-5.3 and Claude 4.1, indicating that Gemma variants are competitive in real-world testing.
Despite its inventiveness, Gemma is far behind other frontier agents. According to Arena.AI’s leaderboard ranking, Anthropic’s variant, Claude Opus 4.6 and 4.7 thinking models, scale high on the leader board across various domains. On the contrary, Gemma 4 31B ranks at 39th position, and Gemma 4 26B A4B falls to the 57th. These positions show a wide gap between open-source models and enterprise systems.
While Gemma 4 12B possesses efficiency, it succumbs to an ecosystem where reasoning is at its core. This shows that Google is prioritizing deployability and efficiency over scaling benchmarks. While frontier models still score high, Gemma 4 models demonstrate competitiveness and potential.
Also Read: Gemma 4 12B Ranks as Highly Efficient Google Multimodal ModelGoogle NotebookLM Could Get 3 Major New Features – Personal Preferences, Connectors, and Canvas
What Makes Gemma 4 12B Unique?
According to Google’s blog, Gemma 4 12B is different because of its encoder-free architecture. The usual multimodal systems depend on distinct image and audio encoders to change non-textual inputs. These inputs are then passed on to the language model. This leads to increased latency and memory usage. Gemma 4 12B removes this disparity and embeds visual inputs in a single matrix multiplication, allowing the language model to process images.
Audio processing is further simplified by removing the encoder and transitioning audio signals to the same dimension as the visual data. This feature reduces latency and makes multimodal information interpretable for users. This is a key aspect of Gemma, the new model, and is its comprehensive goal.
Why Does Local Deployment Matter?
The model is small, with 16GB of RAM, suitable for multimodal models. This resonates with a push toward offline AI systems that do not depend on cloud connectivity. Native deployment helps developers create multimodal models interacting with infographics, audio, and text. Combined with its Apache 2.0 license, Gemma 4.0 is an accessible foundation for creation across research and autonomous developers. The model also includes a multi-token prediction that lets it create various tokens at once and streamline the workflow in a responsive mobile-first environment.
Gemma brings a crucial shift in open-source models, showing how simplicity in AI infrastructure can create multimodal intelligence models. Its encoder-free architecture and reduced latency support show that practical deployment scales. While it also has limitations compared to frontier systems, Gemma’s foremost distinguishing feature lies in local deployment.












