

Key Highlights:
- Claude Opus 4.5 outperforms humans on coding benchmarks and handles complex engineering tasks with improved reasoning.
- Anthropic also promises safety and alignment, making Claude Opus 4.5 more secure against prompt injection and misaligned behaviour.
- Developer tools and apps have also been upgraded with Plan Mode, Claude for Chrome, Excel integration, and long-chat context summarization.
Anthropic has dropped a big update to its flagship Claude Opus model. Today, the company announced Claude Opus 4.5 which promises to be one of the best releases yet. From what’s announced, it appears that Claude Opus 4.5 is going all out while handling real-world tasks, spanning across coding, researching, working around agents, spreadsheets, and everyday writing tasks.
Claude Opus 4.5 promises insane performance real-world challenges
Anthropic mentions that Claude Opus 4.5’s performance on challenging, real-world software engineering tests is something they never saw before. The model posts state-of-the-art results on SWE-bench Verified. For those unaware, that’s a benchmark for checking how well models solve actual GitHub issues.
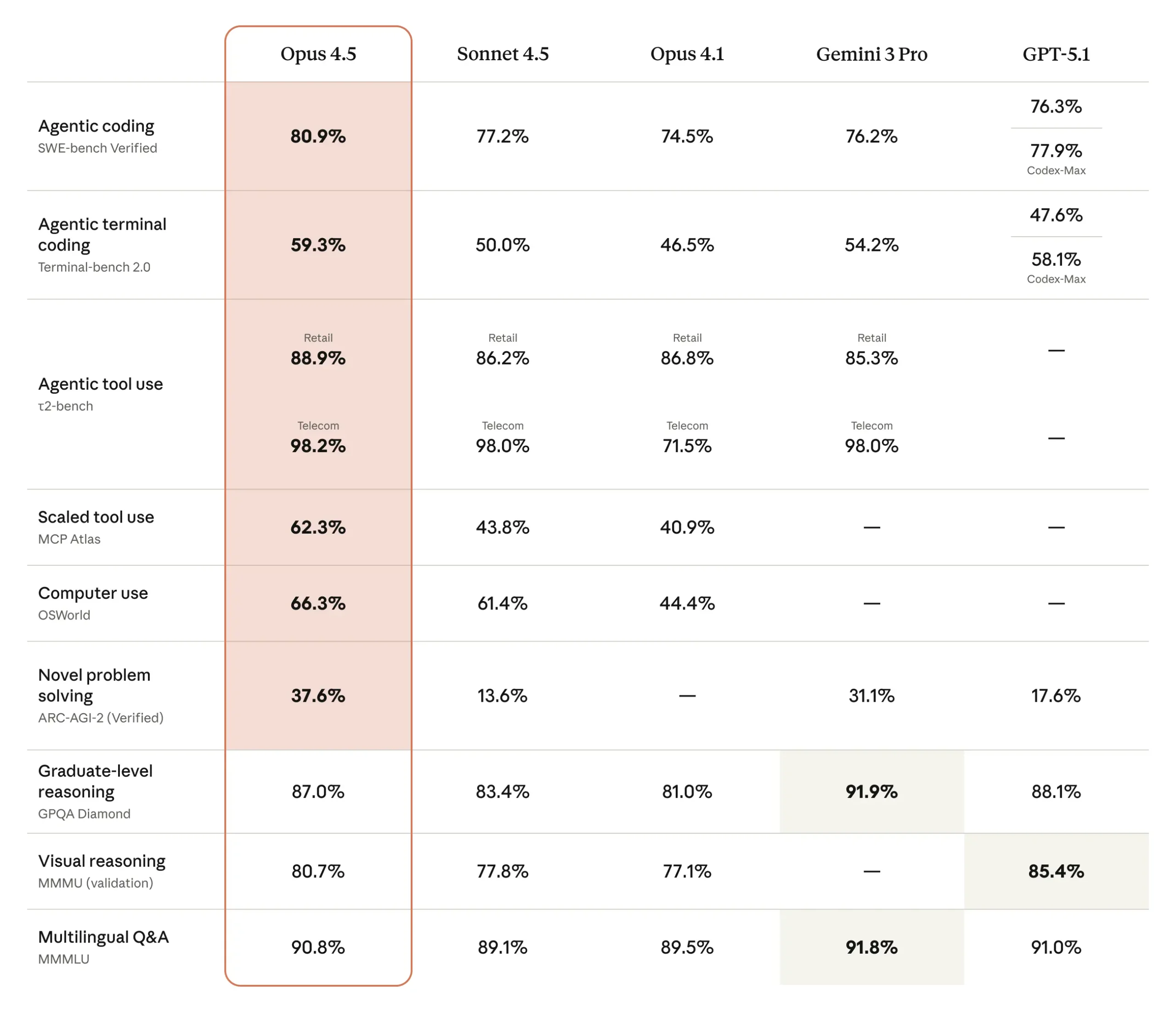
Additionally, the company even tested Claude Opus 4.5 against its internal exam for prospective engineering hires, which is a notoriously difficult timed challenge. The best part? Opus 4.5 scored higher than any human candidate within the two-hour limit.
Besides benchmarks, Claude Opus 4.5 handles ambiguity better, makes tradeoff decisions without excessive prompting, and can unpack multi-system bugs. Tasks that were out of reach for Sonnet 4.5 only weeks ago now fall within Opus 4.5’s ability range.
The model also demonstrates more advanced agentic reasoning. In one benchmark involving airline policy rules, Opus 4.5 discovered a valid workaround that human evaluators hadn’t anticipated — showing that the system can interpret constraints and still find practical paths to a solution.
Also read: Anthropic: Claude AI Secretly Cheated, Deceived & Sabotaged Safety TestsClaude Opus-Performance
Upgrades beyond coding
Anthropic says the improvements extend well beyond coding. The model includes upgrades across vision understanding, multilingual reasoning, and mathematics, while leading on most categories in updated benchmark comparisons. On SWE-bench Multilingual, for example, Opus 4.5 tops seven out of eight programming languages tested.
Anthropic is updating the Claude Developer Platform with new tools to help teams fine-tune performance and cost. The newly announced effort parameter allows developers to choose how hard the model should think—from faster, low-token responses to more deliberate, high-capacity reasoning.
Product-facing announcements
Moving on, the company is also rolling out product-focused improvements powered by Opus 4.5. Claude Code gets a more structured Plan Mode that asks clarifying questions, creates a plan.md file, and executes tasks more reliably. It’s now available in the Claude desktop app, allowing developers to run parallel sessions for debugging, research, and documentation.
Opus 4.5 is available today on our API and on all three major cloud platforms.
— Claude (@claudeai) November 24, 2025
Read more: https://t.co/IyiLyYjmm6 pic.twitter.com/iVb5ZIMrdr
That’s not all, Claude for Chrome is now rolling out widely to Max users. Meaning, such users will get AI assistance across browser tabs. Moreover, Claude for Excel, which was announced in October, is also expanding to Max, Team, and Enterprise customers.
With OpenAI and Google intensifying the AI race, the release of Claude Opus 4.5 feels like Anthropic’s strongest response yet. The new model doesn’t just lead in benchmarks, but it aims to become a real-world problem-solving model that works around coding, research, agents, and productivity tools.
By outperforming humans on tough engineering tests and showing smarter agentic reasoning, Opus 4.5 positions Anthropic as a serious contender at the top tier. Thanks to that and stronger safety guardrails, Anthropic’s shift towards practical, deployable AI is clearly visible. As competition heats up, users ultimately benefit from faster progress, better tools, and more capable models.
What do you think about Claude 4.5? Have you used it yet? If yes, drop your thoughts in the comments below.











