Key Highlights:
- DeepSeek has launched its new open-weight AI model, Math-V2, which is designed for high-precision math reasoning and formal proof generation.
- The model combines a theorem generator and a verifier to produce and validate rigorous step-by-step proofs.
- Math-V2 uses self-verification to overcome limitations of traditional RL-based reasoning and boost proof-level accuracy.
If you keep tabs on what’s going on in the AI industry, you probably know what DeepSeek is. Like ChatGPT, Claude, Gemini, it’s an AI assistant that comes from China. To catch you up, it took the AI industry by storm earlier this year when it introduced the R1 model, which reportedly matched OpenAI’s o1 model and was quick to make its marks because it was affordable too. However, DeepSeek was later caught in massive scrutiny, and there have been several reports related to security concerns associated with it. Now, the company has dropped a new model, and it appears that it’ll also rival models from the likes of Google and OpenAI.
How DeepSeek-Math-V2 goes beyond traditional reinforcement-learning models
The Chinese AI startup has launched a new open-weight AI model specifically designed for high-precision math reasoning and theorem proving. The model, DeepSeek-Math-V2, can both generate and self-verify mathematical proofs, which goes beyond the typical reasoning strength of mainstream Large Language Models (LLMs). As DeepSeek notes, Math-V2 focuses mainly on rigorous, step-by-step derivation and not just simply providing a correct final answer.
The new model is publicly available under the Apache 2.0 open-source license. If you are a developer pr researcher, you can get it from platforms like Hugging Face and GitHub. Worth noting that Math-V2 is developed on top of DeepSeek-V3.2-Exp. The latter is an experimental reasoning model that DeepSeek introduced back in September this year. Speaking of Match-V2, it consists of two core components:
- A theorem generator, capable of producing formal mathematical proofs and correcting its own mistakes.
- A verifier that checks those proofs line by line to ensure they meet mathematical standards.
DeepSeek mentions that this design helps address the fundamental limitations of mainstream reinforcement-learning-based reasoning. Currently, most models available in the market are reportedly trained to maximize the accuracy of the final answer. However, when solving problems from tests like AIME or HMMT, but fails when problems require proof-level logic. That’s where the Match-V2 model comes in handy, according to DeepSeek.
Speaking of which, DeepSeek, in its technical paper, notes, “Higher final answer accuracy does not guarantee correct reasoning.” The company points out that theorem proving demands careful derivation rather than shortcut guessing. To fix this, Math-V2 uses self-verification as a form of deeper test-time compute, which essentially allows the model to perform long-form reasoning and then audit itself until it reaches a provably correct solution. DeepSeek claims this process allows the AI to tackle open mathematical problems where answers are not known in advance.
Also read: Is DeepSeek AI a Game-Changer in the AI Chatbot Revolution?
DeepSeek-Math-V2 matches elite AI models in Olympiad-level tests
DeepSeek’s Math-V2 performance puts it in the same league as OpenAI and Google DeepMind, whose unreleased internal models have achieved nearly the same level of gold-medal scores on IMO 2025 benchmarks earlier this year. However, it is worth noting that DeepSeek wasn’t allowed to participate, and neither was OpenAI — making DeepSeek’s independently published results even more significant for the open-source community right now.
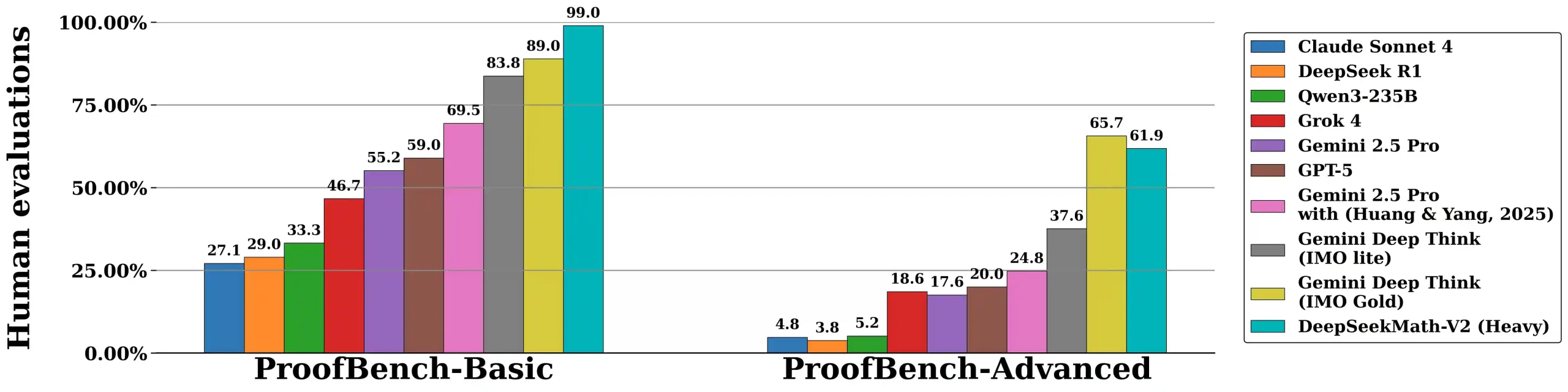
In internal tests, DeepSeek-Math-V2 delivered what the company calls gold-medal-level performance when tested on difficult problems from the International Mathematical Olympiad (IMO 2025) and the CREST Mathematics Olympiad (CMO 2024). The model reportedly scored at levels comparable with top human competitors. It also achieved an impressive 118/120 on a set of problems derived from the prestigious Putnam 2024 math competition — considered one of the toughest undergraduate mathematics contests in the world.

DeepSeek, pointing at these findings, says the results not only highlight the potential of self-verifiable mathematical reasoning but are also theoretically promising and represent a feasible research direction that could help shape future mathematical AI systems. While companies like OpenAI and Google continue to move ahead with closed, high-scale reasoning models, the release of Math-V2 gives the open-source ecosystem a rare contender that doesn’t hide behind proprietary walls.